О теории вероятностей
1. Предмет и основные понятия ТВ
ТВ – математическая наука изучающая закономерность в массовых однородных случаях, явлениях и процессах.
Элементарные события – это простейшие не разложимые результаты опыта. Вся совокупность элементарных событий – пространство элементарных событий.
Под опытом в ТВ понимается выполнение некоторого комплекса условий в результате которого происходят или не происходят некоторые события – факты.
Событие в ТВ – это любое конечное или счетное подмножество пространства W.
Три типа событий:
· Достоверные
· Случайные
· Невозможные.
События являются несовместными если они не могут происходить одновременно и наоборот.
Элементы последовательность попарно несовместны, если любые два из них попарно несовместны.
Несколько событий равновозможные, если ни одно из них не имеет объективного преимущества перед другим. События образуют полную группу если в результате опыта ничего кроме этих событий не может произойти.
Алгебра событий.
1) Суммой двух событий А + В = АÈВ называется такое третье событие которое заключается в наступлении хотя бы одного из событий А или В (или).
2) Произведением двух событий А*В = АÇВ называется такое третье событие, которое заключается в наступлении двух событий одновременно (и).
3) Отрицанием события А является событие `А, которое заключается в ненаступлении А.
4) Если наступление события А приводит к наступлению события В и наоборот, то А=В.
Пусть множество S – это множество всех подмножеств пространства всех элементов W для которых выполняются следующие условия:
1. Если АÎ S, B Î S, то A+B = AÈB Î S
2. Если АÎ S, B Î S, то А*В = АÇВ Î S
3. Если АÎ S, то `А Î S.
Тогда множество S называется алгеброй событий.
При точном подходе достаточно одного из этих свойств, так как каждое из них следует из другого.
При расширении операции сложения и умножения, на случай счетного множества событий, алгебра событий называется бролевской алгеброй.
2. Определение вероятности события.
Аксиоматическое определение вероятности.
Вероятность события – это численная мера объективной возможности его появления.
Аксиомы вероятности:
· Каждому событию А ставится в соответствие неотрицательное число р, которое называется вероятностью события А. Р(А)=р ³ 0, где АÎ S, SÍW.
· Р(W) = 1, где W - истинное (достоверное) событие.
Аксиоматический подход не указывает, как конкретно находить вероятность.
Классическое определение вероятности.
Пусть событие А1,А2, …, АnÎ S (*) образуют пространство элементарных событий, тогда событие из * которое приводит к наступлению А, называют благоприятствующими исходами для А. Вероятностью А называется отношение числа исходов благоприятствующих наступлению события А, к числу всех равновозможных элементарных исходов.
| (А)= | m(A) |
| Рn |
Свойства вероятности:
1. 0 £ Р(А) £ 1,
2. Р (W) =1,
3. Р (`W) = 0.
Статическое определение вероятности.
Пусть проводится серия опытов (n раз), в результате которых наступает или не наступает некоторое событие А (m раз), тогда отношение m/n, при n®¥ называются статистической вероятностью события А.
Геометрическое определение вероятности.
Геометрической вероятностью называется отношение меры области, благоприятствующей появлению события А, к мере всей области.
3. Интегральная функция распределения и ее свойства
Для непрерывной случайной величины X вероятность Р(Х= xi)→0, поэтому для НСВ удобнее использовать вероятность того, что СВ Х<хi, где хi- текущее значение переменной. Эта вероятность называется интегральной функцией распределения: P(X
Интегральная функция является универсальным способом задания СВ (как для ДСВ, так и для НСВ).
Свойства интегральной функции распределения:
1) F(x) не убывает (если х2>x1, то F(x2)≥Р(х1));
2). F(-∞)=0;
3). F(+∞)=1;
4) вероятность попадания СВ X в интервал а<Х
P(a≤X
Замечание. Обычно для определённости левую границу включают в интервал, а правую нет. Вообще для НСВ верно, что
Р(а≤Х
4. Основные теоремы теории вероятностей
Теорема1.
Вероятность суммы двух несовместных событий А и В равна сумме их вероятностей:
Р(А+В)=Р(А)+Р(В).
Следствие1.
Если А1,А2, …, Аn- попарно несовместные события, то вероятность их суммы равна сумме вероятностей этих событий.
Следствие2.
Вероятность суммы попарно несовместных событий А1,А2, …, Аn, образующих полную группу, равна 1.
Следствие3.
События А и `А несовместны и образуют полную группу событий, поэтому
Р(А +`А) = Р(А) + Р(`А) = 1. Отсюда Р (`А) = 1 – Р(А).
Теорема2.
Вероятность суммы двух совместных событий А и В равна сумме вероятностей этих событий без вероятности их произведения:
Р (А+В) = Р(А)+Р(В) – Р (А*В).
Два события А и В называются независимыми, если появление одного из них не влияет на вероятность появления другого (в противном случае события зависимы).
Теорема3.
Вероятность произведения двух независимых событий равна произведению их вероятностей Р(А*В)=Р(А)*Р(В).
Следствие.
Вероятность произведения n независимых событий А1,А2, …, Аn равна произведению их вероятностей.
Условной вероятностью события В при условии, что событие А уже произошло, называется число Р(АВ)/Р(А)=Р(В/А)РА(В).
Теорема4.
Вероятность произведения двух зависимых событий А и В равна произведению вероятности наступления события А на условную вероятность события В при условии что событие А уже произошло:
Р(А*В) =Р(А)*Р(В/А).
Следствие.
Если события А и В независимы, то из теоремы 4 следует теорема 3.
Событие В не зависит от события А, если Р(В/А) = Р(В). Теорему 4 можно обобщить на n событий.
Теорема5.
Вероятность произведения n зависимых событий А1,А2, …, Аnравна произведению последовательных условных вероятностей:
Р(А1*А2*…*Аn-1*An)= P(A1)*P(A2/A1)*...*P(An/A1*A2*...*An-1).
Теорема6.
Вероятность наступления хотя бы одного из событий А1,А2, …, Аnравна разности между единицей и вероятностью произведении отрицаний событий А1,А2, …, Аn:
Р(А)=1-Р(`А1*`А2*…*`Аn)=1- P(`A1)*P(`A2/`A1)*...*P(`An/`A1*`A2*...*`An-1).
Следствие1.
Вероятность наступления хотя бы одного из событий А1,А2, …, Аnнезависимых в совокупности, равна разности между единицей и произведением вероятностей противоположных событий:
Р(А)=1-Р(`А1)Р(`А2)…Р(`Аn).
Следствие2.
Если события А1,А2, …, Аnнезависимы и имеют одинаковую вероятность появиться (Р(А1)=Р(А2)=…Р(Аn)= р, Р(Аi)= 1-р=q ), то вероятность появления хотя бы одного из них равна Р(А)=1-qn .
5. Формулы полной вероятности и вероятности гипотез
Пусть событие А может наступать только одновременно с одним из попарно несовместных событий Н1, Н2, ..., Нn, образующих полную группу. Тогда вероятность события А определятся по формуле полной вероятности:
Р(А) = Р(Н1)*P(А/Н1) + Р(Н2)*Р(А/Н2) +...+ Р(Нn)*Р(А/Нn), или Р(А)= Σ Р(Нi)*Р(А/Нi),
где события Н1,Н2, ...,Нn, - гипотезы, a P(A/Hi) - условная вероятность наступления события А при наступлении i-ой гипотезы (i=1, 2,..., n).
Условная вероятность гипотезы Нi при условии того, что событие А произошло, определяется по формуле вероятности гипотез или формуле Байеса (она позволяет пересмотреть вероятности гипотез после наступления события А):
Р(Нi/А)=(P(Hi)*P(A/Hi))/P(A).
6. Формула Бернулли
Пусть некоторый опыт повторяется в неизменных условиях n раз, причём каждый раз может либо наступить (успех), либо не наступить (неудача) некоторое событие А, где Р(А) = р - вероятность успеха, Р(А)=1-р= q - вероятность неудачи. Тогда вероятность того, что в к случаях из n произойдёт событие А вычисляется по формуле Бернулли
Pn(K) = Ckn-pk-qn-k.
Условия, приводящие к формуле Бернулли, называются схемой повторных независимых испытаний или схемой Бернулли. Так как вероятности Рn(к) для раз личных значений к представляют собой слагаемые в разложении бинома Ньютона
(p+q)n=C0n*p0*qn+C1n*p1*qn-1+…+Ckn*pk*qn-k+…+Cnn*pn*q0,
то распределение вероятностей Pn(k), где 0≤k≤n, называется биноминальным.
Если в каждом из независимых испытаний вероятности наступления события А разные, то вероятность наступления события А к раз в n опытах определяется как коэффициент, при к-ой степени полинома
φn(Z)=Π(qi+piZ)=anZn+an-1Zn-1+…+a1Z1+a0, где φn(Z) - производящая функция.
Невероятнейшее число наступивших событий в схеме Бернулли - ко (к0 c К) определяется из следующего неравенства: np-q≤k0≤np+p.
7. Локальная формула Муавра-Лапласа
Если npq>10 , то
![]()
где вероятность р отлична от 0 и 1 (р→0,5), х =(k-np)/√npq.
Для облегчения вычислений функция
![]()
представлена в виде таблицы (прил.1).
φ(х) - функция вероятности нормального распределения (рис. 6) имеет следующие свойства:
1) φ(х)-четная;
2) точки перегиба х = ± 1;
3) при х≥5, φ(х)→0, поэтому функция φ(х) представлена в виде таблицы для 0≤х≤5 (прил.1).
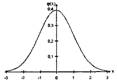
Рис. Функция вероятности нормального распределения
8. Интегральная теорема Муавра-Лапласа.
При больших значениях n , для вычисления вероятности того, что произойдет от к1, до к2 событий по схеме
![]()
Бернулли, используется интегральная формула Муавра-Лапласа
Pn(k1≤k≤k2)=Ф(x2)- Ф(x1),
где x1=(k1-np) /(√npq), x2=(k2-np)/(√npq), Ф(x) – функция Лапласа. (рис.7)
Ф(х) имеет следующие свойства:
1. Ф(-х)= -Ф(х) - функция нечетная, поэтому достаточно изучать её для неотрицательных значений х
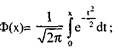
2. Функция Ф(х) возрастает на всей числовой оси;
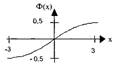
Рис. Функция Лапласа
3. При х≥5, Ф(х)→1/2 (y = 0,5 горизонтальная асимптота при х>0), поэтому функция представлена в виде таблицы Для 0≤х≤5 (прил.1).
4. Вероятность отклонения относительной частоты от постоянной вероятности в независимых испытаниях не более чем на некоторое число ε>0
![]()
9. Формула Пуассона
Если npq<10 и р<0,1, то
![]() где λ=np.
где λ=np.
10. Случайные величины и их виды
Случайной величиной (СВ) называют такую величину, которая в результате опыта может принимать те или иные значения, причем до опыта мы не можем сказать какое именно значение она примет. (Более точно, СВ - это действительная функция, определенная на пространстве элементарных событий Q). Случайные величины обозначаются последними буквами латинского алфавита - X,Y,Z. Случайные величины могут быть трех типов: - дискретные, - непрерывные, - смешанные (дискретно-непрерывные). Дискретная случайная величина (ДСВ) может принимать конечное или бесконечное счетное число значений. Непрерывная случайная величина (НСВ) в отличие от ДСВ принимает бесконечное несчетное число значений. Например мишень имеет форму круга радиуса R. По этой мишени произвели выстрел с обязательным попаданием. Обозначим через Y расстояние от центра мишени до точки попадания, Ye (0; R). Y - непрерывная случайная величина, так как она принимает бесконечное несчетное число значений.
Пусть X - дискретная случайная величина, которая принимает значения х1, х2, ...,хn,... с некоторой вероятностью рi, где i = 1, 2, ..., n,... Тогда можно говорить о вероятности того, что случайная величина X приняла значение хi: рi=Р(Х=хi).
ДСВ может также представляться в виде многоугольника распределения – фигуры, состоящей из точек, соединенных отрезками. Над СВ устанавливаются операции сложения и умножения.
Суммой двух СВ X и Y наз-ся случайная величина, которая получается в рез-те сложения всех значений случайной величины X и всех значений СВ Y, соответствующие вероятности перемножаются. Произведением двух СВ X и Y наз-ся СВ, которая получается в рез-те перемножения всех значений СВ X и всех значений СВ Y, соответствующие вероятности перемножаются.
11. Математическое ожидание
Математическим ожиданием М(Х) ДСВ X называется среднее значение случайной величины:
![]()
Или иначе, М(Х) - это сумма парных произведений случайной величины на соответствующую вероятность:
![]()
Мода Мо(Х) распределения - это значение СВ, имеющее наиболее вероятное значение.
Медиана Ме(Х) - это значение случайной величины, которое делит таблицу распределения на две части таким образом, что вероятность попадания в одну из них равна 0,5. Медиана обычно не определяется для ДСВ.
Свойства математического ожидания:
1) М(С)=С, где С=const;
2)М(СХ) = СМ(Х);
3) M(X±Y) = М(Х) ± M(Y);
4) Если случайные величины X и Y, независимы, то M(XY) = M(X)*M(Y).
Для биномиального распределения М(Х)=nр;
для геометрического распределения М(Х)= 1/р;
для распределения Пуассона М(Х)=λ;
для гипергеометрического распределения М(Х) = n(M/N).
12. Дисперсия ДСВ и ее свойства
Математическое ожидание квадрата отклонения СВ от ее математического ожидания:
D(X) = M(x-M(X)2) = =(х1-М(Х))2р1+(х2-М(Х))2р2+....+(xn-М(Х))2рn .(2.3.2)
Свойства дисперсии:
1) D(С) = 0, где С=соnst;
2) D(CX)=C2D(X);
3) D(X)=M(X2)-(M(X))2, где М(Х2) = х21 р1 + x22 p2 + ...+ х2n рn;
4) Если СВ X и Y независимы, то D(X±Y)=D(X) + D(Y);
5) D(OX)=D(X);
6) Для любых СВ X и Y, D(X±Y)=D(X)+D(Y)±2cov(X,Y), где cov(X,Y)=M((X-mx)(Y-m )) - ковариация случайных величин X и Y (М(Х)= mx, M(Y)= m).
Дисперсия характеризует средний квадрат отклонения ДСВ, поэтому на практике часто используют в качестве характеристики разброса среднее квадратическое отклонение σ(Х)= √D(X) , которое имеет ту же размерность, что и СВ X.
Для биноминального закона
D(X)=npq, σ(X)=√npq;
для геометрического закона D(X)= q/p2;
для гипергеометрического D(X)=n(M/N)(1-M/N)(N-n)/(N-1);
для распределения Пуассона D(X)=λ.
Только для распределения Пуассона M(X)=D(X)= λ.
13. Показательное распределение.
НСВ X, принимающая неотрицательные значения, имеет показательное распределение, если ее дифференциальная функция имеет вид
![]()
где Я =const, Я >0.
Интегральная функция показательного закона с параметром λ:
![]()

Рис. Показательный закон
Если СВ X распределена по показательному закону, то:
1. Математическое ожидание М(Х) = 1/λ ;
2. Дисперсия D(X)=1/λ2, среднее квадратическое отклонение
σ(X)=√D=1/λ.
3. Вероятность попадания СВ X в заданный интервал определяется по формуле
Р(а≤х
Замечание. Показательное распределение играет большую роль в теории массового обслуживания (ТМО), теории надежности. В ТМО параметр X - среднее число событий, приходящихся на единицу времени. При определенных условиях число событий, произошедших за промежуток времени т, распределено по закону Пуассона с математическим ожиданием а =λτ. Длина промежутка t, между произвольными двумя соседними событиями, подчиняется показательному закону: P(T
14. Закон распределения дискретной случайной величины
1. Биномиальный закон распределения. Случайная величина X принимает значения 0, 1, 2, 3, 4, 5,...,n, с вероятностью, определяемой по формуле Бернулли:
![]()
2. Закон распределения Пуассона. Случайная величина X принимает бесконечное счетное число значений: 0, 1, 2, 3, 4, 5,..., к,... , с вероятностью, определяющейся по формуле Пуассона:
![]()
где Х>0 - параметр распределения Пуассона.
![]()
При n→∞ и р→0 биномиальный закон приближается к закону распределения Пуассона, где λ, = np.
Геометрический закон распределения. Пусть Р(А)=р - вероятность наступления события А в каждом опыте, соответственно, q=l-p - вероятность не наступления события А.
Вероятность наступления события А в к-ом опыте определяется по формуле:
P(X=k)=p-qk-1. (2.2.2.)
Случайная величина X, распределенная по геометрическому закону принимает значения 1, 2,...,к,... , с вероятностью, определяемой по формуле (2.2.2):
![]()
4. Гипергеометрический закон распределения. Пусть в урне N-шаров, из них М белых, а остальные (N - М) черные. Найдем вероятность того, что из извлеченных n шаров m белых и (n-m) черных.
N= М + (N-M); n = m + (n-m);
СmM - число способов выбора m белых шаров из М;
Сn-mN-M- число способов выбора (n-m) черных шаров из (N-M).
По правилу произведения, число всех возможных наборов из m белых и (n-m) черных равно СmM Сn-mN-M;
CnN- общее число способов выбора из N шаров n.
Отсюда, по формуле классического определения вероятности, P(A)= (СmM Сn-mN-M)/ CnN
Ограничения на параметры: М≤N, m≤n; m = m0, m0 +1, m0+2,..., min(M,n), где m0=max{0, n-(N-M)}. Случайная величина Х, распределенная по гипергеометрическому закону распределения (при т=0,1,2,3,...,М), имеет вид:
![]()
Гипергеометрический закон определяется тремя параметрами N, М, n. При n<0,1N этот закон стремится к биномиальному.
Замечание.
1. В теории вероятностей различают две основные схемы: выбора элементов с возвращением каждый раз обратно и выбора без возвращения, которые описываются соответственно биномиальным и гипергеометрическим законами.
2. Геометрический закон описывает схему повторения опытов (в каждом из которых может наступить или не наступить событие А: Р(А)=р, q=l-p), до первого появления события А, то есть фактически это отрицательное биномиальное распределение при m=1.
16. Одинаково распределённые, взаимонезависимые дискретные случайные величины
СВ называют одинаково распределенными, если они имеют одинаковые законы распределения. Поэтому у них совпадают числовые характеристики: математическое ожидание, дисперсия, среднее квадратическое отклонение.
Пусть X1, Х2,..., Хn одинаково распределенные, взаимонезависимые ДСВ, тогда:
M(X1) = М(Х2) = ... = М(Хn) = М(Х), D(X1) = D(X2) = ...= D(Xn)=D(X).
Рассмотрим характеристики их средней арифметической X = (X1+X2+…+Xn)/n:
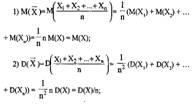
![]()
![]()
-стандартное отклонение СВ X.
Дисперсия относительной частоты (m/n) появления события А в n независимых испытаниях (в каждом из которых событие А появляется с вероятностью равной р, и не появляется с вероятностью q= 1-р; m-число появлений события А в серии из n испытаний), определяется по формуле
15. Дифференциальная функция распределения и ее свойства
СВ X непрерывна, если ее интегральная функция непрерывна на всей числовой оси. СВ X непрерывна и имеет дифференциальную функцию, если ее интегральная функция непрерывна и дифференцируема всюду, за исключением конечного числа точек на любом конечном промежутке.
Дифференциальной функцией (функцией плотности вероятности) СВ X называется производная ее функции распределения: f(x)=F'(x).
С помощью дифференциальной функции можно получить формулу вероятности попадания СВ X в заданный интервал:
![]()
Свойства дифференциальной функции:
). f(x)≥0;
![]()
![]()
16. Числовые характеристики непрерывных случайных величин
1) Математическое ожидание НСВ X определяется по формуле
М(Х)= ∫xf(x)dx. (2.7.1)
Если НСВ X определена на интервале (а; b), то
М(Х)= ∫xf(x)dx.
2) Мода НСВ X будет определяться как максимум ее дифференциальной функции: Мо(Х) = max f (x).
3) Медиана определяется как значение случайной величины, которое делит площадь под дифференциальной функцией на две равные части. Me(X): P(x
4). Дисперсия НВС
![]()
Все св-ва дисперсии и мат-го ожидания, установленные для ДСВ, сохраняется для НСВ.
Замечание. Если распределение симметрично, то его мода, медиана и математическое ожидание совпадают.
5). Моменты случайных величин.
Кроме характеристик положения и рассеяния существует ряд других числовых характеристик распределения, например, моменты.
Начальным моментом порядка s называется математическое ожидание степени s CB X: αs=M(Xs).
Для ДСВ:
![]()
![]()
При s=l:α1, = M(X) = mx, то есть, первый начальный момент - это математическое ожидание СВ.
Отклонение СВ от ее математического ожидания называется центрированной СВ X: X = Х-mх.
Центральным моментом порядка s СВ X называется математическое ожидание степени s, соответствующей центрированной СВ: μs=μ(Xs)=M((x-M(X))s).
![]()
![]()
При вычислении центральных моментов пользуются формулами связи между центральными и начальными моментами:
μ1=0,
μ2=α2-m2x,
μ3=α3-3mxα2+2m3x,
μ4=α4-4mxα3+6m2xα2-3m4x.
Обычно рассматривают первые четыре центральных момента:
1). μ1=M(x-mx)=0 – мат-ое ожидание центрированной СВ равно нулю;
2). μ2= M(x-mx)2=D(X) – второй центральный момент – это дисперсия;
3). μ3= M(x-mx)3- третий центральный момент может служить для характеристики асимметрии, обычно рассматривают безразмерный коэффициент асимметрии
Sk=μ3/σ3.
4). Четвёртый центральный момент
μ4=M(x-mx)4,
может служить для характеристики “крутости” или островершинности распределения, описывающиеся с помощью эксцесса:
Ex=(μ4/σ4)-3.
Основным моментом порядка s называется нормированный центральный момент порядка s:
rs= μs/σs, то есть Sk=r3, Ex=r4-3
17. Равномерный закон распределения
СВ X распределена по равномерному (прямоугольному) закону, если все значения СВ лежат внутри некоторого интервала и все они равновероятны (точнее обладают одной плотностью вероятности).Например, если весы имеют точность 1г и полученное значение округляется до ближайшего целого числа k, то точный вес можно считать равномерно распределенной СВ на интервале (k-0,5; k+0,5).
Дифференциальная функция равномерного закона на интервале (α,β) (рис. 11):
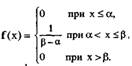
Интегральная функция равномерного закона на интервале (α,β) (рис. 11):
![]()

Рис. Дифференциальная функция
2). Интегральная функция.
Основные числовые характеристики равномерного закона:
1. Математическое ожидание
![]()
М(Х) совпадает, в силу симметрии распределения, с медианой.
Моды равномерное распределение не имеет.
Дисперсия

Отсюда, среднее квадратическое отклонение
![]()
Третий центральный момент
![]()
поэтому распределение симметрично относительно М(Х).
Четвёртый центральный момент
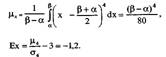
Вероятность попадания СВ в заданный интервал (а;b). Пусть СВ X распределена по равномерному закону,
18. Закон больших чисел
Под законом больших чисел в теории вероятностей понимают совокупность теорем, в которых утверждается, что существует связь между средним арифметическим достаточно большого числа случайных величин и средним арифметическим их математических ожиданий.
В1927 г. Гейзенберг открыл принцип неопределенности, который утверждает, что измерительное познание ограничено. Неопределенность является неотъемлемой частью нашей жизни, однако, при большом числе однотипных опытов можно установить определенные закономерности.
19. Нормальный закон распределения
Нормальный закон распределения играет исключительную роль в теории вероятностей. Это наиболее часто встречающийся закон распределения, главной особенностью которого является то, что он является предельным законом, к которому, при определённых условиях, приближаются другие законы распределения.
Дифференциальная функция нормального закона имеет вид
![]()
Числовые характеристики нормального закона:
1. Математическое ожидание характеризует центр распределения
![]()
где ex=exp(x);
2. Дисперсия характеризует форму распределения
![]()
Свойства дифференциальной функции нормального закона:
1. Область определения: Df = R;
2. Ось ОХ - горизонтальная асимптота;
3. х = а±σ - две точки перегиба;
4. Максимум в точке с координатами (а; 1/(σ√2π);
5. График симметричен относительно прямой х=а;
6. Моменты:
μ1=μ3=…=μ2k+1=…=0,
μ2=σ2, μ4=3σ4,
Sk=μ3/σ3=0, Ex=μ4/σ4-3=0
7. Вероятность попадания нормально распределенной случайной величины в заданный интервал определяется, по свойству интегральной функции
![]()
где
![]()
интегральная функция нормального закона (рис.14); Ф(х)- функция Лапласа.
Свойства интегральной функции нормального закона:
1. Ф* (-∞)=0;
2. Ф*(+)=1;
3. Ф*(x)=1/2+Ф(x);
4. Ф*(-x)=1-Ф*(x).
Вероятность заданного отклонения. Правило трех сигм.
Найдем вероятность того, что случайная величина X, распределённая по нормальному закону, отклонится от математического ожидания М(Х)=а не более чем на величину ε>0.
Р(|х-а|<ε)= Р(-ε< х-а<+ε) = Р(а-ε<х< а+е) =Ф*((a+ε-a)/σ)-Ф*((a-ε-a)/σ)=Ф*(ε/σ)-(1-Ф* (ε/σ))=2Ф* (ε/σ)-1.
Или, используя функцию Лапласа:
P(|X-a|<ε)=2Ф(ε/σ).
Найдём вероятность того, что нормально распределённая СВ X отклонится от M(X)=a на σ, 2σ, 3σ:
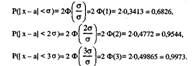
Отсюда следует правило Зσ. если случайная величина X имеет нормальное распределение, то отклонение этой случайной величины от ее математического ожидания по абсолютной величине не превышает утроенное среднее квадратическое отклонение (Зσ).
20. Многомерные случайные величины
В практических задачах приходится сталкиваться со случаями, когда результат описывается двумя и более случайными величинами, образующими систему случайных величин (случайный вектор). Например, точка попадания снаряда имеет две координаты: х и у, которые можно принять за систему случайных величин, определенных на одном и том же пространстве элементарных событий Ω.
Закон распределения дискретной двумерной случайной величины можно представить в виде таблицы, характеризующей собой совокупность всех значений случайных величин и соответствующих вероятностей:
x1 | x2 | … | xn | Σ P(yj) | |
y1 | P(x1,y1) | P(x2,y2) | … | P(xn,y1) | P(y1) |
y2 | P(x1,y2) | P(x2,y2) | … | P(xn,y2) | P(y2) |
| … | … | … | … | … | … |
ym | P(x1,ym) | P(x2,ym) | … | P(xn,ym) | P(ym) |
Σ Pxi | P(x1) | P(x2) | … | P(xn) | 1 |
В общем случае двумерная случайная величина задается в виде интегральной функции, которая означает вероятность попадания двумерной случайной величины в квадрант левее и ниже точки с координатами (х, y):
F(x, у) = Р(Х<х, Y
21. Свойства интегральной функции:
1. F - не убывает и непрерывна слева по каждому аргументу.
2. F(-∞, у)= F(x,-∞)= F(-∞, -∞)= 0.
3. F(+∞, у)= F2(y) - функция распределения случайной величины Y. F(x,+∞)= F1,(x) - функция распределения случайной величины X.
4. F(+∞,+∞)=l.
Вероятность попадания двумерной случайной величины в прямоугольник определяется исходя из определения интегральной функции двумерной случайной величины:
Р((х, у) c D) = F(β,δ) - F(α,β) - F(β,γ) + F(α,γ).
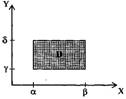
Рис. Вероятность попадания точки (х, у) в прямоугольник D
Случайные величины X, Y независимы, если
F(x, у) = = F1(x)* F2(y).
Дифференциальная функция системы двух непрерывных случайных величин определяется как вторая смешанная производная функции распределения:
f(x,y)=(∂2F(x,y))/∂x∂y=F″xy(x,y).
Свойства дифференциальной функции:
l.f(x,y)>0;
![]()
![]()
Геометрически свойство 2 означает, что объем тела, ограниченного поверхностью f (x, у) и плоскостью XOY, равен 1.
Если случайные величины X и Y независимы, то
f(x,y) = f1(x) f2(y), где f1(x)=F’1(x),f2(y)=F’2(y).
В противном случае
f ( x , у ) = f1( x ) f ( y / x )
или f ( x, y) = f2( y ) f (x / y ),
где f(y/x)=f(x,y)/f1(x) - условная дифференциальная функция CB Y при заданном значении
X = x, f(y/x)=f(x,y)/f2(x) - условная дифференциальная функция СВ X при заданном значении Y= у;
![]() - дифференциальные функции отдельных случайных величин X и Y, входящих в систему.
- дифференциальные функции отдельных случайных величин X и Y, входящих в систему.
22. Числовые характеристики системы двух случайных величин. Корреляционный момент. Коэффициент корреляции
Начальным моментом порядка s,h системы двух случайных величин X, Y называется математическое ожидание произведения степени s случайной величины X и степени h случайной величины Y:
αs,h=M(XsYh)
Центральным, моментом порядка s, h системы СВ (X, Y) называется математическое ожидание произведения степеней s, h соответствующих центрированных случайных величин:
μs,h =M(XSYh), где X =X-М(X),
Y=Y-М(Y)
-центрированные случайные величины X и Y.
Основным моментом порядка s, h системы СВ (X,Y) называется нормированный центральный момент порядка s, h:
Начальные моменты α1.0, α0,1
α1.0=M(X1Y0)=M(X); α0.1=M(X0Y1)=M(Y).
Вторые центральные моменты:
μ2,0=M(X2Y0)=M(x-M(X))2=D(X)
- характеризует рассеяние случайных величин в направлении оси ОХ.
μ2,0 = M(X0Y2) = M(y-M(Y))2 = D(Y)
- характеризует рассеяние случайных величин в направлении оси OY.
Особую роль в качестве характеристики совместной вариации случайных величин X и Y играет второй смешанный центральный момент, который называется корреляционным моментом - K(X,Y) или ковариацией –
cov(X,Y): μ1,1=K(X,Y)=cov(X,Y)=M(X1Y1)=M(XY)-M(X)M(Y).
Корреляционный момент является мерой связи случайных величин.
Если случайные величины X и Y независимы, то математическое ожидание равно произведению их математических ожиданий:
М (XY)= М (X) М (Y), отсюда cov(X,Y)=0
Если ковариация случайных величин не равна нулю, то говорят, что случайные величины коррелированны. Ковариация может принимать значения на всей числовой оси, поэтому в качестве меры связи используют основной момент порядка s=1, h=1 ,который называют коэффициентом корреляции:

Свойства коэффициента корреляции:
1. -1
2. Если r = +1, то случайные величины линейно зависимы;
3. Если rху = 0, то случайные величины некоррелированны, что не означает их